6 – Datenjournalismus

© Illustration: Smaranda Tolosano für GIJN
von Purity Mukami and Emilia Díaz-Struck
Die Verwendung von Daten im Journalismus ist nicht neu, aber in den letzten Jahrzehnten hat sich viel getan. In den 1960er Jahren begann Philip Meyer bei der Detroit Free Press mit dem Einsatz von Computern zur Datenverarbeitung für verschiedene Projekte zu experimentieren. Er führte auch die Verwendung sozialwissenschaftlicher Methoden in der Berichterstattung ein, die er später in seinem 1973 erschienenen Buch „Precision Journalism: A Reporter’s Introduction to Social Science Methods“ detailliert beschrieb.
Im Laufe der Zeit folgten immer mehr dem Beispiel des Journalisten Meyer. 1989 startete die Organisation Investigative Reporters and Editors (IRE) mit Unterstützung der Missouri School of Journalism in den USA das Programm National Institute for Computer-Assisted Reporting. Von da an wurden Journalist*innen darin geschult, wie sie Daten in ihren Recherchen verwenden oder sogar Recherchen aus Daten erstellen können.
In den folgenden Jahrzehnten – analog zur Verbreitung des Internets und der Entstehung von Datenmengen – begannen Journalist*innen, den Begriff „Datenjournalismus“ zu verwenden, um damit Recherchen zu beschreiben, bei denen die Datenerfassung und -analyse ein wesentlicher Bestandteil des Rechercheprozesses war. Sie deckten mithilfe von Daten systemische Probleme auf, identifizierten Muster und Ausreißer und konnten so auf neue Art und Weise über Themen von öffentlichem Interesse berichten.
Infolgedessen wurde die computergestützte Berichterstattung zu einer globalen Praxis, wie der ehemalige IRE-Geschäftsführer Brant Houston feststellte: Journalist*innen weltweit, einzeln oder als Teil regionaler oder sogar internationaler Organisationen, begannen, Computer und Daten für ihre Recherchen zu nutzen. Gleichzeitig begannen Universitäten und Organisationen auf der ganzen Welt, Schulungen zum Thema Datenjournalismus anzubieten. (So auch das das Global Investigative Journalism Network).
Heute, 60 Jahre nachdem Meyer mit Computern zu experimentieren begann, sind viele investigative Projekte das Ergebnis der Verarbeitung großer Mengen von Datensätzen und der Durchführung von Datenanalysen mit Computern, kombiniert mit traditionellen Recherchemethoden wie dem Gespräch mit Quellen, der Berichterstattung vor Ort und dem Zugriff auf öffentliche Aufzeichnungen und Dokumente, um Geschichten von öffentlichem Interesse zu produzieren.
Wo man Daten findet
Daten sind überall. Dank der technologischen Fortschritte der letzten Jahrzehnte können Menschen mehr Informationen als je zuvor speichern und verarbeiten. Inzwischen können Daten in aggregierter oder granularer Form vorliegen. Natürlich ziehen es Journalist*innen oft vor, granulare Daten zu erhalten, damit sie aus allen Blickwinkeln analysiert werden können. Das ist jedoch nicht immer der Fall.
Viele Regierungen begrüßen die Veröffentlichung von Daten. Einige Quellen, mit denen man anfangen kann, sind:
- Unternehmensregister
- Gerichtsakten
- Grundbuchämter
- Amtsblätter. Diese sind in den meisten Rechtsprechungen öffentlich
- Aus Regierungs- oder NGO-Websites extrahierte öffentliche Datenbanken. (Prüft vorher die rechtlichen Bestimmungen der Gerichtsbarkeit oder der Unternehmen, die die Daten hosten. Einige haben Einschränkungen oder besondere Regeln in Bezug auf Scraping haben.)
- Selbst undurchsichtige Länder wie die DR Kongo und Burkina Faso veröffentlichen Bergbauinformationen über Systeme, die Landrechte und -beschränkungen verwalten.
- Updates von Regierungsbeamten und Strafverfolgungsbehörden über ihre sozialen Medien, Websites und offiziellen Kanäle (Beispiel).
- Internationale Organisationen wie die Vereinten Nationen
Wenn eine Organisation oder eine öffentliche Behörde eine Zahl (z. B. eine Statistik) veröffentlicht, könnte die Frage nach den zugrunde liegenden Daten auch eine Möglichkeit sein, auf einen Datensatz zuzugreifen.
Einige Beispiele für öffentlich zugängliche Datensätze sind:
- UK Land Registry
- Datenbank für CO2-Ausgleich und -Gutschriften
- CITES-Handelsdatenbank
- Congo Mining Cadastre (Register)
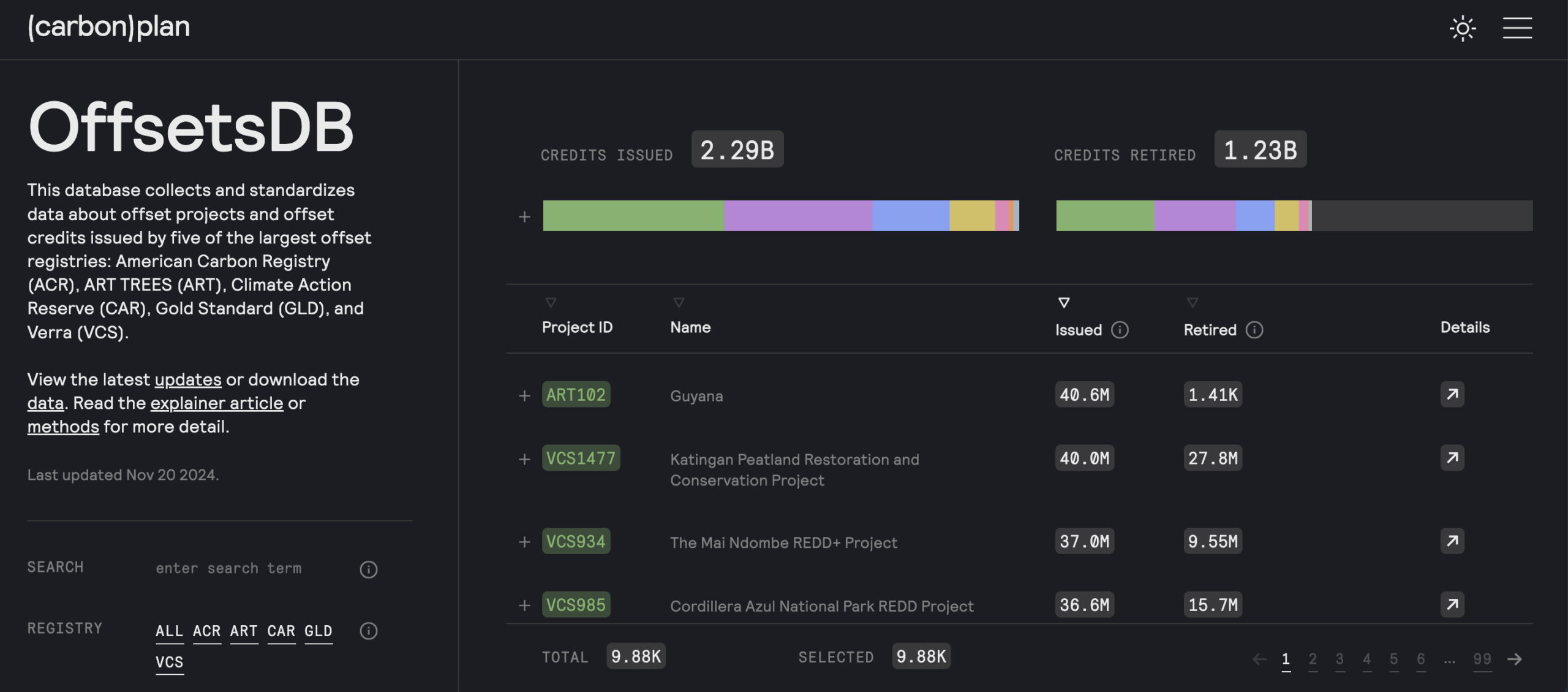
Der Rechercheprozess
Datenjournalismus ist mehr als nur die Erstellung von Diagrammen und Infografiken und mehr als nur die Arbeit mit strukturierten Daten in Tabellenkalkulationen. Es geht darum, Daten zu nutzen, um Verborgenes aufzudecken und die Recherche voranzutreiben.
Um Daten effektiv für Recherchen zu nutzen, fragt euch:
- Was ist die Art der Datenquelle: Wo und wie werden die Daten gespeichert?
- Sind die Daten strukturiert oder unstrukturiert?
- Worauf liegt der Schwerpunkt der Geschichte und in welchem Format wird sie erzählt?
- Über welche Kapazitäten verfügt das Team?
- Welche Daten sind verfügbar? Wenn keine vorhanden sind, können sie erstellt werden?
Dann legt ihr los:
1. Daten beschaffen. Sobald sich eine Idee als verfolgenswert erwiesen hat, besteht der nächste Schritt darin, die Daten zu beschaffen. Journalist*innen erhalten Daten durch das Durchsickern eines Datensatzes oder von Dokumenten, durch das Einreichen von IFG-Anfragen, durch Quellen, durch die Programmierung, um Daten aus Dokumenten oder Webseiten zu extrahieren, oder durch das Extrahieren aus PDFs und anderen Bilddokumenten. Diese Daten gilt es dann in strukturierte Daten umzuwandeln, die leicht analysiert werden können.
In einigen Fällen müssen Journalist*inneen möglicherweise ihren eigenen Datensatz erstellen, wenn dieser nicht bereits in einem strukturierten Format vorliegt – beispielsweise über Dokumente oder andere Quellen.
2. Daten verstehen. Prüft nach, wer die Daten erstellt hat, d. h. ermittelt die Datenquelle, überprüft die Referenzen und beurteilt die Glaubwürdigkeit. Lest dafür die Dokumentation zur Datenquelle, um herauszufinden, wie die Daten erfasst wurden. Außerdem solltet ihr herausfinden, ob die Daten aus einem primären oder einem sekundären Datensatz stammen, der aus anderen Datenquellen erstellt wurde. Was enthalten die Daten (versteht die Variablen, was sie darstellen und wie sie gespeichert werden). Identifiziert, ob es sich bei den vorliegenden Daten um den vollständigen Datensatz oder nur um einen Teil davon handelt.
Versucht anschließend zu verstehen, welche Fragen die vorliegenden Daten beantworten können. Achtet dabei darauf, was fehlt und möglicherweise durch zusätzliche Datenquellen ergänzt werden muss. Recherchiert, ob es einen weiteren Datensatz gibt, um den ursprünglichen Datensatz zu erweitern oder mit ihm zu vergleichen.
3. Daten überprüfen. Stellt sicher, dass die erhaltenen Daten authentisch sind und bestätigt werden können. Daten können durch Querverweise mit anderen Datensätzen, die Überprüfung anderer Dokumente und Gespräche mit Expert*innen verifiziert werden. Im späteren Verlauf der Recherche sollten Journalist*innen die in den Datensätzen direkt erwähnten Personen oder Organisationen kontaktieren, um Kommentare und Verifizierungen einzuholen.
Bei der Arbeit mit Daten können Probleme wie Datengenauigkeit, Vollständigkeit und Inkonsistenz auftreten. Prüft daher genau, ob es Probleme mit den Daten gibt und ob die Informationen nicht authentisch, veraltet oder unvollständig sind. Andernfalls könnte die Recherche wacklig werden.
4. Daten dokumentieren und sichern. Wenn ihr die Daten neu strukturiert, denkt daran, eine README-Datei, also eine Anleitung, über die Daten und eure Recherche-Methodik zu erstellen. Macht euch während der Arbeit mit den Daten Notizen über eure Schritte. Das hilft, Fehler zu reduzieren. Bewahrt eine Kopie der Originaldaten auf – im Falle eines Fehlers ist es so leichter möglich, ihn bis zu seinem Ursprung zurückzuverfolgen.
Legt außerdem fest, wer mit den Daten arbeitet. Je nach Sensibilität der Daten ist es wichtig zu entscheiden, wer auf die Daten zugreifen darf und wie sie weitergegeben werden. Daten können in Ordnern, auf einem Google Drive, über eine Flash-Disk (wenn sie zu sensibel sind, um sie im Internet zu speichern), über Datenbanken, z. B. gemeinsam nutzbare SQL-Datenbanken, oder mithilfe fortschrittlicher Tools wie Aleph, Datashare, NINA usw. gespeichert werden.
Ein Beispiel ist auch NINA, die Datenplattform des lateinamerikanischen Zentrums für investigativen Journalismus (El CLIP) verbindet offene Datenbanken, um die Suche nach Verbindungen zwischen Unternehmen und Einzelpersonen, die von lateinamerikanischen Regierungen beauftragt wurden, zu vereinfachen.
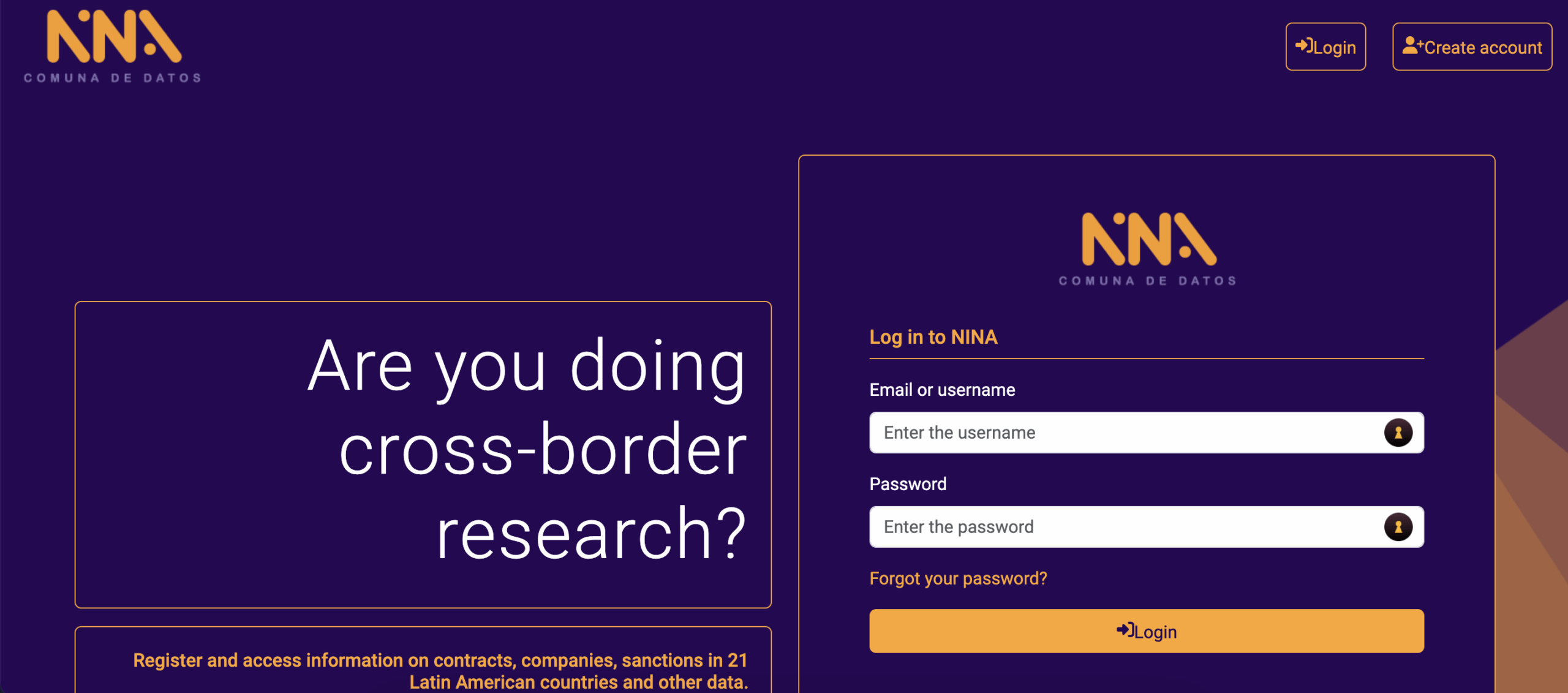
Das Organized Crime and Corruption Reporting Project (OCCRP) und das International Consortium of Investigative Journalists (ICIJ) tauschen in der Regel Daten mit allen an einem Projekt beteiligten Journalist*innen aus, um eine effiziente Zusammenarbeit zu ermöglichen. Dennoch haben diese Organisationen strenge Protokolle, die festlegen, wer auf einen Datensatz zugreifen darf, um Quellen oder Reporter*innen nicht zu gefährden, und stellen gleichzeitig sicher, dass alle Personen mit Zugriff über alle Informationen und den erforderlichen Kontext verfügen, um den Datensatz vollständig zu verstehen. Mit anderen Worten: Gebt die die Daten nur an diejenigen weiter, die darauf zugreifen müssen.
5. Daten analysieren, um Erkenntnisse zu gewinnen. Sobald ihr die Daten verstanden und mit anderen Mitarbeiter*innen geteilt habt, könnt ihr mit der Auswertung beginnen. Behandelt die Daten immer so, wie ihr andere Quellen behandelt – befragt die Daten. Fragt euch, welche Fragen die Daten beantworten können, und dokumentiert, wie ihr zu diesen Antworten gelangt:
- Führt ein Datentagebuch über die Schritte, die unternommen wurden, um zu einem Wert oder einer Erkenntnis zu gelangen. Dies hilft bei der Überprüfung von Fakten oder wenn Fragen von Redakteur*innen oder Anwält*innen gestellt werden.
- Verwendet außerdem selbstreferenzierende und reproduzierbare Prozesse, um Fragen später beantworten zu können. Dazu könnte die Verwendung von Excel-Formeln anstelle des Kopierens und Einfügens von Daten gehören, die Verwendung von Programmiercodes, die Verwendung eines GitHub-Repositorys oder andere Methoden, um die Arbeit zu verfolgen.
- Haltet die Ergebnisse so fest, dass ihr und andere Teammitglieder sie leicht nachvollziehen können. Entwickelt systematische Methoden zur Speicherung der Berechnungen, z. B. über Tabellenkalkulationen, Dashboards, Python-Code oder eine Wiki-Seite.
Im Rahmen der Analyse ist es möglich, die Informationen mit anderen Datensätzen zu vergleichen. So konnten beispielsweise durch den Abgleich von Daten von in Offshore-Gerichtsbarkeiten registrierten Unternehmen, die in den Pandora Papers auftauchten, mit Daten aus Grundbuchämtern im Vereinigten Königreich, Frankreich und den Vereinigten Staaten (Kalifornien, Miami und andere Bundesstaaten) im Rahmen der investigativen Zusammenarbeit zwischen dem ICIJ und mehr als 150 Medienpartnern viele Immobilien aufgedeckt werden, die sich heimlich im Besitz von Politikern und Personen des öffentlichen Lebens befanden.
6. Überprüft die Ergebnisse mit zusätzlicher Recherche. Die Datenanalyse muss überprüft werden, um sicherzustellen, dass die Ergebnisse Sinn ergeben. Diese müssen anhand der geltenden Gesetze und Vorschriften oder sogar anhand früherer Forschungsarbeiten und Berichte überprüft werden. Sprecht mit Expert*innen und überprüft die Analyse mit Kolleg*innen.
Fragt euch:
- Decken die Daten ein Fehlverhalten auf (Geldwäsche, Korruption, Steuerhinterziehung, Umweltverstöße oder andere Straftaten)?
- Gibt es Probleme mit der Gültigkeit der Daten?
- Enthalten die Daten neue Informationen?
- Tragen die Daten dazu bei, ein systemisches Problem zu beleuchten?
- Gibt es einen überraschenden Ausreißer in den Daten, der zu einer wichtigen Geschichte werden könnte?
Oft muss man nur lange genug suchen, bis man etwas in den Daten findet. Aber Achtung: Statistiken können manipuliert werden, um Schlussfolgerungen zu stützen. Das muss man natürlich vermeiden.
7. Plant die Veröffentlichung. Wenn ihr eure Analyse abgeschlossen habt, plant Zeit für die Überprüfung der Ergebnisse der Datenrecherche ein, schreibt eure Geschichte und überprüft, ob die Daten im richtigen Kontext dargestellt werden. Plant wie bei anderen investigativen Beiträgen eine juristische Überprüfung ein und nehmt euch Zeit für die Produktion. Plant ihr eine Visualisierung oder ein interaktives Element zu der Geschichte zu veröffentlichen? Nehmt das ebenfalls in den Plan auf.
Von den Daten zur Geschichte
Eine Datenstory kann auf die gleiche Weise beginnen wie andere Storys: im Rahmen der Berichterstattung über eine andere Story, ein Leak oder sogar eine Beobachtung – einige Themen von öffentlichem Interesse können auch die Produktion von Daten vorantreiben, die zu Storys führen.
In diesen Fällen sind es oft die Daten, die die Storys antreiben.
Auch wenn die Kombination von Datenrecherche und traditioneller Recherche sehr wirkungsvolle Ergebnisse hervorbringen kann, ist es dennoch wichtig, die menschliche Komponente und das öffentliche Interesse im Auge zu behalten. Warum sollte die Zielgruppe an der Geschichte interessiert sein? Welches systemische Problem wird aufgedeckt? Wer ist von diesem Problem betroffen?
Von den Daten zur Geschichte: eine Checkliste
- Identifiziert euren Blickwinkel für die Geschichte. Eine Datenanalyse kann überfordernd sein und viele mögliche Blickwinkel eröffnen. Grenzt den Blickwinkel ein, indem ihr euch eure Recherchehypothese klar macht. Wenn euch das immernoch nicht hilft, sprecht mit Kolleg*innen oder Redakteur*innen. Ein frischer Blick kann helfen, den besten Interpretationsrahmen zu finden, einen neuen zu entwickeln und wertvolles Feedback zu erhalten.
- Storyboarding und Storyplanung. Die Darstellung der Ergebnisse in einem Storyboard hilft dabei, die Aspekte einer guten Geschichte zu organisieren und zu definieren, wie z. B. die Charaktere, den Konflikt, die Handlung, die Struktur usw. Schreibt auf: Was ist die fesselnde Handlung in Ihren wichtigsten Erkenntnissen?
- Schreibt den Pitch. Erklärt, wohin die Daten führen, damit andere, einschließlich der Redakteur*innen, euch verstehen und auf den gleichen Stand kommen können.
- Recherchiert zu den Daten. Denkt daran, dass großartige Datenstorys immer auch von einer großartigen Recherche begleitet werden. Ein Beispiel: Stellt euch vor, ihr analysiert Wohnbauprojekte in eurem Land und werft einen genauen Blick auf die Investitionen der Regierung und die mit dem Bau der Wohnungen beauftragten Unternehmen. Bei der Besichtigung der Standorte der Wohnbauprojekte, die ihr in den Datensätzen gefunden habt, stellt ihr fest, dass es dort gar keine Gebäude gibt. In diesem Fall wird die Diskrepanz zwischen den Daten und dem, was vor Ort geschieht, zur Geschichte.
- Schreibt die Geschichte. Die größte Herausforderung bei datengestützten Recherchen besteht darin, die Ergebnisse durch kohärente und ansprechende Geschichten zum Leben zu erwecken. Es kann hilfreich sein, die Geschichte zu skizzieren oder zu diagrammatisieren, bevor ihr mit dem Schreiben beginnt
- Daten-Downloads, Erläuterungen und Visualisierungen: Überlegt euch bei der Planung der Veröffentlichung, ob es Daten gibt, die öffentlich zugänglich gemacht oder mit dem Publikum geteilt werden können, um das Verständnis der Leser*innen für das Thema zu verbessern. Man kann diese zum Beispiel in Form einer interaktiven Grafik darstellen oder zum Download zur Verfügung stellen. Außerdem sollte man einen methodischen Begleitartikel schreiben, der die Art der Daten und die Art und Weise, wie mit den Daten gearbeitet wurde, erklärt.
Denkt immer daran: Das Publikum interessiert sich nicht immer für Rohdaten, daher ist eine sorgfältige und kreative Erzählweise und visuelle Präsentation wichtig, damit die Daten einen Sinn ergeben.
Das Tolle an Datenstorys ist, dass sie die Möglichkeit bieten, mit einer Reihe von Methoden zu experimentieren, um die Daten zu vermitteln. Die Ergebnisse können beispielsweise als Tweet oder TikTok-Post verpackt oder über eine Infografik oder ein Video präsentiert werden. Nachrichtenredaktionen verwenden oft mehr als eine Methode, um ihre Print- oder Videoberichte zu begleiten.
Visualisierungen der Daten können den Rechercheprozess unterstützen und auch ein Endprodukt sein.
Wichtig ist außerdem, Grafik- und andere Teams frühzeitig einzubeziehen. Wenn sie erst spät in den Prozess einbezogen werden, bleibt wenig Zeit, um den Daten die visuelle Aufbereitung zu geben, die sie verdienen.
Weitere Überlegungen
Faktencheck
Wenn ihr mit Daten arbeitet, plant Zeit für den Faktencheck ein:
- Wenn manuelle Einträge in eine Tabelle vorgenommen wurden, plant Zeit dafür ein, zu überprüfen, ob die Einträge korrekt vorgenommen wurden. Wenn die Ressourcen verfügbar sind, bittet andere, die nicht an den Daten beteiligt sind, die Dateneinträge zu überprüfen (je nach Komplexität der Daten kann man zwei bis drei Überprüfungsrunden einplanen).
- Wenn jemand eine Analyse durchgeführt hat, reproduziert diese Analyse, um zu überprüfen, ob die gleichen Ergebnisse erzielt werden. Wichtig ist hier, eine zweite Person, die die Analyse reproduziert und bei der Faktenprüfung hilft, mit einzubeziehn.
- Plant Zeit ein, um zu überprüfen, wie die Ergebnisse der Analyse in der Geschichte dargestellt werden und ob sie im richtigen Kontext dargestellt werden. Überprüft auch die Visualisierungen und interaktiven Elemente, um sicherzustellen, dass sie die Informationen und die Ergebnisse der Datenanalyse widerspiegeln.
Denkt daran: Wenn die Daten wasserdicht sind, ist auch die veröffentlichte Geschichte wasserdicht.
Kollaboration bei Datenrecherchen
Die Arbeit mit Daten kann von einzelnen Datenjournalist*innen oder einem Datenteam gemeinsam gemacht werden. Je nach Umfang der Daten und den Ressourcen der Organisation kann die Arbeit mit einem Datensatz mehr als eine Person erfordern.
Gleichzeitig können Datenteams von einer Mischung von Fähigkeiten profitieren und innerhalb desselben Teams sowohl aus Expert*innen für Forschung und Datenanalyse als auch Entwickler*innen bestehen. Wenn die Daten in Umfang, Struktur und Format komplex werden, kann es hilfreich sein, ein interdisziplinäres Team zu bilden.
Rechercheprojekte, die mit großen Datensätze arbeiten sind oft Teamarbeiten, an denen Reporter*innen, Datenjournalist*innen, Rechercheur*innen, Fakten-Checker, Online-Produzent*innen, Redakteur*innen und auch Nicht-Journalist*innen beteiligt sind.
Zum Beispiel können Ingenieur*innen Tools entwickeln, die den Bedürfnissen der Journalist*innen gerecht werden und zum Beispiel Modelle für maschinelles Lernen entwickeln, um Millionen von Datensätzen zu durchsuchen oder andere Technologien im Dienste von Journalist*innen einsetzen und so bei der Verarbeitung von Millionen von Datensätzen helfen.
Auch internationalen Kooperationen profitieren von Daten, da sie Journalist*innen aus verschiedenen Ländern bei der Zusammenarbeit miteinander verbinden.
Manchmal braucht es die Hilfe von Organisationen, die größere oder erfahrenere Datenteams haben. Aus diesem Grund sollten Journalist*innen oder Teams die Zusammenarbeit mit Organisationen wie ICIJ, OCCRP, Pulitzer Center oder Lighthouse Reports oder die Partnerschaft mit einer Universität mit einer Informatikabteilung in Betracht ziehen. Dies gilt insbesondere, da diese Organisationen über größere dedizierte Datenteams verfügen als die meisten Nachrichtenredaktionen, in denen es möglicherweise nur ein oder zwei „Datenexpert*innen“ gibt.
Wenn ihr Daten mit anderen Organisationen oder sogar Ihren Teamkolleg*innen im eigenen Haus teilt, stellt sicher, dass ihr transparent macht, woher die Daten stammen, wie sie analysiert wurden und welche Einschränkungen die Daten haben.
Wichtig bei der Arbeit in interdisziplinären Teams ist eine gute Kommunikation während des gesamten Prozesses, damit alle auf dem gleichen Stand sind, was das Verständnis der Ziele des Projekts und die Art und Weise seiner Durchführung betrifft.
Werkzeugkasten
Seid ihr neu in der Datenrecherche? Hier sind einige Kurse und Tools für euch:
- Um Tabellenkalkulationen zu beherrschen, schaut euch die Grundlagen von Google Sheets von Mark Horvit an. Coursera oder edX bieten inzwischen kostenlose Videokurse in Excel an. Hillfreich ist auch dieser Artikel von Brant Houston.
- Das Handbuch für Datenjournalismus 1 und 2 des Europäischen Journalismuszentrums.
- Python
- R
- SQL
- Open Refine
- PDF-Verarbeitungstools wie
- Tabula
- Poppler
- pdfplumber/pdfminer
- Tools zur Dateiverarbeitung, -exploration und -zusammenarbeit:
- Verwendung der Befehlszeile. Die Grundlagen der Befehlszeile kann man in diesem Material zu „Missing Semester at MIT“ nachlesen, geschrieben von Eric Barrett für Kolleg*innen des OCCRP.
- Die Columbia University stellt auch eine Zusammenfassung von Datenjournalismus-Ressourcen zur Verfügung. Das Knight Center for Journalism in the Americas, com und IRE bieten Kurse und Ressourcen an, die dabei helfen, die Verwendung einiger Tools und Programmiersprachen zu verstehen.
Auch auf investigativen Konferenzen auf der ganzen Welt kann man sich weiterbilden, darunter GIJN’s GIJC, Dataharvest, die African Investigative Journalism Conference (AIJC), die lateinamerikanische Konferenz COLPIN, ARIJ’s Annual Forum oder Nicar by IRE, um nur einige zu nennen.
In Deutschland bietet Netzwerk Recherche auf Konferenz wie der NR25, der Datenjournalismuskonferenz SciCar oder auch der Jungen Recherche Möglichkeiten zur Weiterbildung an.
Fallstudien
Captured – Africa Uncensored
Die Serie untersuchte Korruptionsfälle in Kenia im Zusammenhang mit „Betrug bei der Beschaffung und zwielichtigen Ausschreibungen in der Regierung und in Regierungsbehörden“. Das Projekt überprüfte Informationen über die öffentliche Beschaffung und untersuchte Verbindungen zwischen Beamten und anderen Interessengruppen, die über eine Reihe von Unternehmen Vorteile bei Ausschreibungsverfahren erhielten.
Agents of Secrecy – Finance Uncovered, BBC, Seychelles Broadcasting Corporation
Diese Kollaboration nutzten Datenanalysen öffentlich zugänglicher britischer Unternehmensdaten und Tausende durchgesickerter Dokumente, um „die Drahtzieher und Handlanger aufzuspüren, die einige der geschäftigsten Geheimhaltungsagenturen mit Russland-Bezug bilden“. Die Recherche überprüfte die Nutzung anonymer Firmen im Vereinigten Königreich durch Geldwäscher in der gesamten ehemaligen Sowjetunion.
Inside the Suspicion Machine – Lighthouse Reports, WIRED, Vers Beton, Open Rotterdam
„Zwei Jahre lang verfolgte Lighthouse Reports die heilige Dreifaltigkeit der algorithmischen Rechenschaftspflicht: die Trainingsdaten, die Modelldatei und den Code für ein System, das von einer Regierungsbehörde zur Automatisierung von Risikobewertungen für Bürger verwendet wird, die staatliche Dienstleistungen in Anspruch nehmen.“ Nach der Datenbeschaffung analysierte das Team den Algorithmus zur Risikobewertung und fand heraus, wie er Menschen anhand ihrer Muttersprache, ihres Geschlechts und ihrer Kleidung ins Visier nahm.
Pandora Papers – ICIJ und 150 Medienpartner
Fast zwei Jahre lang haben Reporter*innen mehr als 11,5 Millionen Datensätze in verschiedenen Formaten von 14 verschiedenen Offshore-Dienstleistern ausgewertet, um Recherchen zu machen, die „ein Schattenfinanzsystem aufdecken, das den reichsten und mächtigsten Menschen der Welt zugutekommt.“ ihr kombinierten dazu traditionelle Techniken der investigativen Berichterstattung mit fortschrittlicher Datenanalyse. Das Team nutzte Datashare, um die Dateien sicher zu verarbeiten und mit mehr als 600 Reportern auf der ganzen Welt zu teilen, und verwendete verschiedene Tools und Ansätze für die Datenanalyse, darunter maschinelles Lernen, Programmiersprachen wie Python, manuelle Datenarbeit und Graphdatenbanken (neo4j und Linkurious).

Purity Mukami ist eine Statistikerin, die zur Datenjournalistin wurde. Seit sieben Jahren trägt sie mit ihren Datenkenntnissen zu investigativen Geschichten und Projekten wie FinCENFiles, Pandora Papers, Agent of Secrecy und Captured bei. Sie hat bei Africa Uncensored, BBC Africa Eye und Finance Uncovered gearbeitet und ist jetzt Datenjournalistin fürAfrika bei OCCRP. Sie hat mit verschiedenen anderen Organisationen zusammengearbeitet, die Korruption untersuchen, der Spur des Geldes folgen und während Wahlen nach Fehlinformationen Ausschau halten.

Emilia Díaz-Struck ist die Geschäftsführerin des Global Investigative Journalism Network. Zuvor war sie Daten- und Forschungsredakteurin und Koordinatorin für Lateinamerika beim International Consortium of Investigative Journalists (ICIJ). Über ein Jahrzehnt lang war Díaz-Struck an mehr als 20 preisgekrönten investigativen Kooperationen des ICIJ beteiligt, darunter: Offshore Leaks, Implant Files, FinCEN Files, Pandora Papers und die mit dem Pulitzer-Preis ausgezeichneten Panama Papers. Sie leistete Pionierarbeit im Datenjournalismus und bei investigativen Kooperationen in ihrem Heimatland Venezuela und war Mentorin für Hunderte von lateinamerikanischen Reportern. Emilia hat an der Columbia University in New York Sommerseminare über Datenjournalismus und grenzüberschreitende investigative Kooperationen gegeben. ihr war Professorin an der Central University of Venezuela und hat für die Washington Post, das Magazin Poder y Negocios, die venezolanischen Medien El Universal, El Mundo und Armando.info, die sie mitbegründet hat, geschrieben.